Performance Tuning of an Informatica mapping - Source Bottle necks: Create Indexes on key columns which helps reading the source data easily.
- Target: For target if possible use BULK and disable indexes and enable/create them once data loading completes.
- Removing Mapping bottle necks:
- Session bottle necks:
- System Bottlenecks:
Regarding this, how do you handle errors in Informatica?
Error handling properties at the session level is given with options such as Stop On Errors, Stored Procedure Error, Pre-Session Command Task Error and Pre-Post SQL Error. You can use these properties to ignore or set the session to fail if any such error occurs.
Secondly, how does Informatica improve session performance? Avoid transformation errors to improve the session performance. Enable look up cache if your session contains lookup transformation. Drop constraints and indexes before running the session and re-build them after session completion. Because constrains and indexes in target can slow down the loading.
Similarly, it is asked, how can we improve the performance of Informatica mapping?
Performance Tuning in Informatica: Complete Tutorial
- Always prefer to perform joins in the database if possible, as database joins are faster than joins created in Informatica joiner transformation.
- Sort the data before joining if possible, as it decreases the disk I/O performed during joining.
- Make the table with less no of rows as master table.
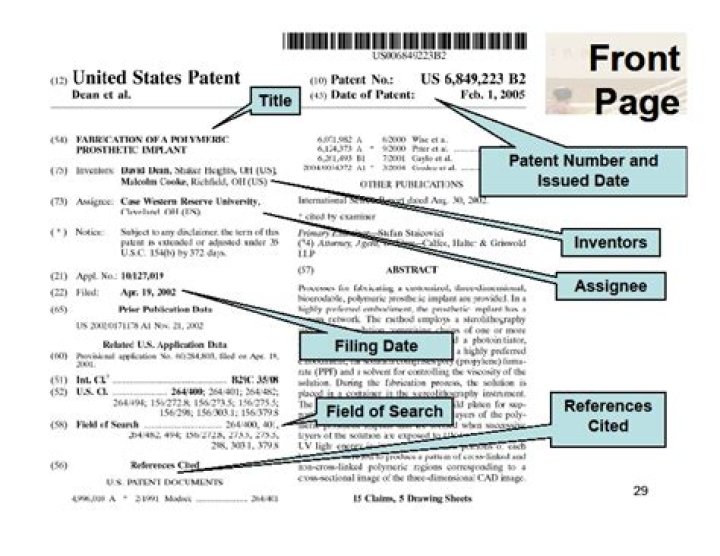
How do you identify performance bottlenecks in Informatica?
Use the following methods to identify performance bottlenecks:
- Run test sessions. You can configure a test session to read from a flat file source or to write to a flat file target to identify source and target bottlenecks.
- Analyze performance details.
- Analyze thread statistics.
- Monitor system performance.
Related Question Answers
What is stop on error in Informatica?
Stop on Errors. This function stops the mapping if a nonfatal error occurs in the reader, writer, or transformation threads. Default is disabled. What is bad file in Informatica?
Bad Files. It's a common term for anyone who is working with Informatica. “It's a Flat File that stores all the Rejected Records which are rejected by the Target” – As simple as that. The File always appends the data to the bad file for each load. What are the error tables present in Informatica?
what are the error tables in Informatica and how we do error handling in Informatica? - – PMERR_DATA. Stores data and metadata about a transformation row error and its corresponding source row.
- – PMERR_SESS. Stores metadata about the session.
- – PMERR_TRANS.
What is Session log in Informatica?
Session Logs Information: Whenever a session runs, the integration service logs the information about the tasks that it performs in a file called session log file. The integration service logs details like load summary, transformation statistics etc. What is the difference between bulk and normal load in Informatica?
The main difference between normal and bulk load is, in normal load Informatica repository service create logs and in bulk load log is not being created. That is the reason bulk load loads the data fast and if anything goes wrong the data cannot be recovered. How can we improve the performance of aggregator transformation in Informatica?
Use the following guidelines to optimize the performance of an Aggregator transformation: - Group by simple columns.
- Use sorted input.
- Use incremental aggregation.
- Filter data before you aggregate it.
- Limit port connections.
Why throughput is less in Informatica?
Source Bottlenecks Performance bottlenecks can occur when the Integration Service reads from a source database. Slowness in reading data from the source leads to delay in filling enough data into DTM buffer. So the transformation and writer threads wait for data. This delay causes the entire session to run slower. How can we increase source throughput in Informatica?
Use filter transformation as early as possible inside the mapping. If the unwanted data can be discarded early in the mapping, it would increase the throughput. ' Use source qualifier to filter the data. What is persistent cache in Informatica?
What is Persistent Cache? Lookups are cached by default in Informatica. This means that Informatica by default brings in the entire data of the lookup table from database server to Informatica Server as a part of lookup cache building activity during session run. What is pushdown optimization in Informatica?
Pushdown optimization is a concept using which you can push the transformation logic on the source or target database side. When you use the SQL override, the session performance is enhanced, as processing the data at a database level is faster compared to processing the data in Informatica. Why we use pushdown optimization in Informatica?
Pushdown optimization technique in informatica pushes the part or complete transformation logic to the source or target database. To preview the SQL statements and mapping logic that the integration service pushes to the source or target database, use the pushdown optimization viewer. What is busy percentage in Informatica?
Busy Time : Percentage of the run time. It is (run time - idle time) / run time x 100. Thread Work Time : The percentage of time taken to process each transformation in a thread. What is pass through partition in Informatica?
Set Partition Point, Add Number of Partition then Partition type. Pass-Through (Default) : All rows in a single partition: No data Distribution. Additional Stage area for better performance. Round-Robin. What is the use of DTM buffer size in Informatica?
?DTM Buffer Size: The DTM buffer size specifies the amount of buffer memory used when the DTM processes a session. Default Buffer Block Size: The buffer block size specifies the amount of buffer memory used to move a block of data from the source to the target. What is DTM in Informatica?
Data Transformation Manager (DTM) process. The PowerCenter Integration Service process starts the Data Transformation Manager process to run a session. The DTM process is also known as the pmdtm process. The DTM process forms partition groups and distributes them to worker DTM processes running on nodes in the grid. Which is better in terms of performance Informatica Joiner transformation vs lookup?
In case of Flat file, generally, sorted joiner is more effective than lookup, because sorted joiner uses join conditions and caches less rows. In case of database, lookup can be effective if the database can return sorted data fast and the amount of data is small, because lookup can create whole cache in memory. What is the maximum DTM buffer size in Informatica?
The DTM buffer size value depends on the amount of memory available on the server hosting the PowerCenter Integration Service. However, an initial value might be 128 MB or 256 MB, entered as 128000000 or 256000000. What is cache in Informatica?
A cache is a memory area where informatica server holds the data to perform calculations during the session run. It creates cache files in the $PMcachedir as soon as the session finishes, server deletes the cache files from the directory. On which database can we configure pushdown optimization?
We can configure sessions for pushdown optimization having any of the databases like Oracle, IBM DB2, Teradata, Microsoft SQL Server, Sybase ASE or Databases that use ODBC drivers. When we use native drivers, the Integration Service generates SQL statements using native database SQL. Which task is used anywhere in workflow to run the shell commands?
Ans: The type of command task that allows the shell commands to run anywhere during the workflow is known as the standalone task. What is session partitioning in Informatica?
Session Partitioning means "Splitting ETL dataload in multiple parallel pipelines threads". It will be helpful on RDBMS like Oracle but not so effective for Teradata or Netezza (auto parallel aware architectural conflict ). Different Type of Partitioning supported by Informatica. What is Commit interval in Informatica?
Informatica Server commits rows based on the number of target rows and the key constraints on the target table is Target Commit. 3. A commit interval is an interval at which the Informatica Server commits data to targets during a session.